環境設定が終わり、基礎的な使用方法を理解しました。実際にコードを打っていくこととします。わたしは本やほかの教材を見つつ、記載しているので書いてみるときには個々で教材を見ながらその通りに打つとよいと思います。
データの概要を確認する
最初に記載するコード
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline
わたしの勉強した教材ではおまじないと言っていましたが確認したところ、
import matplotlib.pyplot as plot
「import matplotlib.pyplot」までで「matplotlib の pyplot という機能を使えるように持ってきます」という意味になります。python の言葉でこのプログラムが matplotlib を使用できるように持ってきています。2段目の
import numpy as np
も同様で「numpy という機能を使えるように持ってきます」という意味になります。
3,4段目はグラフがアウトプット行に出力されるためのものです。plt.show()などを記載することもありますが、plt.show()を省略してもグラフが出力されるため、今回は記載が省略されています(詳細)。
データを読み込んで中身を見てみる
まずはデータの読み込みから始めましょう。以下のコードを記載し、CSV形式のファイルを読み込みます。読み込むファイルはPythonコードを打っているファイルを保存する場所に一緒に入れておいてください。
A = pd.read_csv(“B.csv”)
- Aは読み込んだ後の名前
- “B.csv”は読み込みたいファイル名(csv形式)
読み込みができたら(エラーが発生しなかったら)、今度は最初の5行だけ抽出してデータが入っているかを確かめてみましょう。
A.head()
正しく反映されるとこんな感じで出てきます。
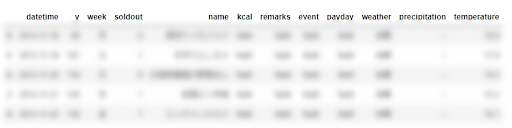
ちなみにtailを使用すると最後から五行抽出されます。
基本統計量を確認してみる
次にざっくりしたデータの傾向を見るためにdescribe関数を使います。describe関数は特に引数を指定しない状態で使われることが多く、とりあえずデータの概要を把握する際に頻繁に使われます。
A.describe()
入っているデータの内容で中身が変わります。今回は数値データを入れているので以下のようなデータが出ます。
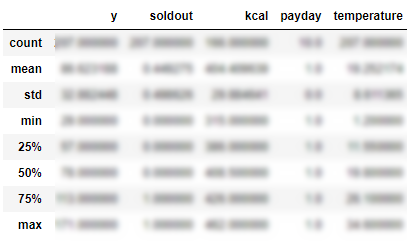
| 表示名 | 説明 |
| count | データの個数を表す |
| mean | 数値データの平均を表す |
| std | 数値データの標準偏差を表す |
| min | 最小値を表します |
| max | 最大値を表します |
| 25%,50%,75% | 四分位数を表します |
ほかにもデータによって表示されるものが違うのでちょっとご紹介します。
カテゴリカルデータ(オブジェクト)
| 表示名 | 説明 |
| count | データの個数を表す |
| unique | ユニークな値がいくつ存在するかを表す |
| top | 最も多く出現した要素の値を表す(最頻値) |
| freq | topで返された値の出現回数を表す |
引数percentilesで分位数指定
また、先ほどは25%,50%,75%でしたが、分位数指定は変更できます。
0~1の間でどの分位数を見たいかを指定します。 デフォルトでは[0.25,0.5,0.75]の3つの値が指定されていますがいくつ設定しても構いません。
In []: s.describe() # 特にpercentilesを指定しない状態
Out[]:In []: s.describe(percentiles=[0.1,0.2,0.5]) # 10%,20%,50%
Out[]:In []: s.describe(percentiles=[0.1,0.2,0.5,0.89]) # 4つ指定することも可能
Out[]:In []: s.describe(percentiles=[0,0.2,0.99]) # 0にすると最小値と一致する。1なら最大値
Out[]:
詳細なデータを確認する
info関数を使用することでデータの大まかな情報を確認することができます。特に「データが欠損していない数」と「データ型」を一つのメソッドで確認することができるのが利点です。データ型によって今後の分析をする際に使用できる関数が変わってきたり、計算ができない場合があるため確認できるのをおすすめします。
A.info()
こんな形で抽出されます。

データ概要が確認できたのでこのあとは細かく分析やデータの可視化ができるようにしていきましょう。
最近のコメント